선형회귀분석(renear regression)
[텐서플로 첫걸음] 2.1 변수 간의 관계에 대한 모델
선형회귀분석은 일정한 입력과 출력을 기반으로 학습을 진행하고 새로운 입력에 대해 출력을 예측하는 모델입니다. 학습을 위해 임의의 랜덤한 입력과 출력 데이터를 생성합니다. 대부분의 머신러닝 교육에서 출력은 레이블(Label)이라고 부르기도 합니다.
이렇게 생성한 임의의 입출력 데이터를 기반으로 최적의 기울기(weight)와 바이어스(bias)를 찾는것이 목표입니다.
# numpy는 파이썬에서 다차원 배열과 행렬을 다루기 위한 높은 수준의 수학함수 라이브러리를 지원합니다.
import numpy as np
num_points = 1000
vectors_set = []
for i in xrange(num_points):
x1 = np.random.normal(0.0, 0.55)
# 랜덤한 데이터 생성을 위해 정규분포를 이용해서 그래프를 흔들어줍니다.
y1 = x1 * 0.1 + 0.3 + np.random.normal(0.0, 0.03) # np.random.normal() = 정규분포
vectors_set.append([x1, y1])
# x_data는 입력을 의미합니다.
x_data = [v[0] for v in vectors_set]
# y_data는 레이블(출력)을 의미합니다.
y_data = [v[1] for v in vectors_set]
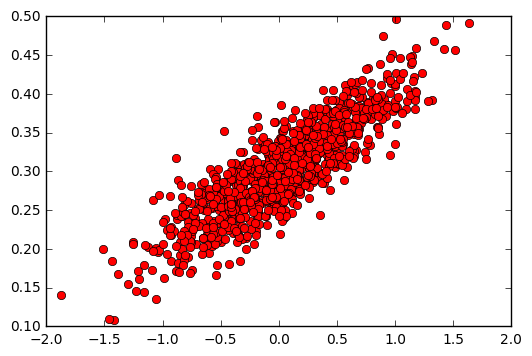
데이터를 그림으로 표현
위에서 생성한 랜덤 데이터를 그래프상에 출력해봅니다.
try:
import matplotlib.pyplot as plt # needs "pip install matplotlib"
plt.plot(x_data, y_data, 'ro')
plt.legend()
plt.show()
except ImportError:
print("Please install matplotlib to visualize embeddings.")
[텐서플로 첫걸음] 2.2 비용함수와 경사 하강법 알고리즘
임의의 랜덤한 데이터로부터 최적의 기울기(W)를 찾습니다.
# 2.1 예제 이후에 이어지는 내용입니다.
import tensorflow as tf
# 마지막에 test_set을 돌려보기 위해 x_data와 y_data를 placeholder로 재지정합니다.
x_data = tf.placeholder(tf.float32)
y_data = tf.placeholder(tf.float32)
# tf.Variable은 TensorFlow에서 변수를 의미합니다.
# 아래 코드는 -1.0 ~ 1.0 사이에 랜덤한 수로 W의 초기값을 설정하겠다는 의미입니다.
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# 비용함수를 계산합니다.
loss = tf.reduce_mean(tf.square(y - y_data))
# 경사 하강법 알고리즘을 사용
optimizer = tf.train.GradientDescentOptimizer(0.5)
# 알고리즘의 최저값을 찾습니다.
train = optimizer.minimize(loss)
# 모든 Variable은 초기화해서 사용해야 합니다.
init = tf.initialize_all_variables()
# 모델을 생성하고 실행시키도록 합니다.
sess = tf.Session()
sess.run(init)
# 학습이 진행될수록 최적의 기울기가 찾아집니다.
for step in xrange(8):
sess.run(train, feed_dict={x_data:[v[0] for v in vectors_set], y_data:[v[1] for v in vectors_set]})
print sess.run(W), sess.run(b)
'''
print 결과
[ 0.13282794] [ 0.30009764]
[ 0.12321223] [ 0.29985777]
[ 0.11645306] [ 0.29973677]
[ 0.11170244] [ 0.29965174]
[ 0.10836352] [ 0.29959196]
[ 0.10601678] [ 0.29954997]
[ 0.10436741] [ 0.29952043]
[ 0.10320815] [ 0.29949969]
'''
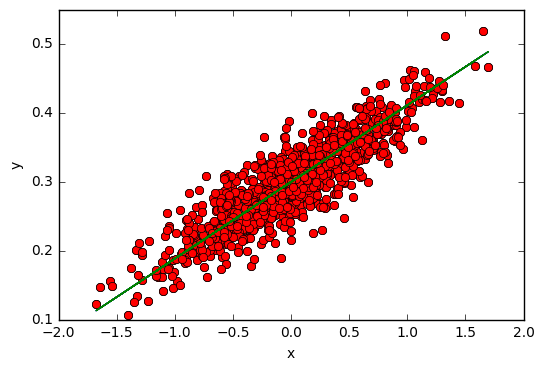
데이터를 그림으로 표현
plt.plot(x_data, y_data, 'ro')
plt.plot(x_data, sess.run(W) * x_data + sess.run(b))
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
학습 데이터 테스트
학습을 마친 후 새로운 데이터에 대해 정확한 분류가 되는지 확인합니다.
test_set = [1,2,3]
print sess.run(y, feed_dict={x_data:test_set})
# Output
# [ 0.38831764 0.47651452 0.56471133]