Lecture 5: Q-learning in non-deterministic world
import gym
import numpy as np
import matplotlib.pyplot as plt
env = gym.make('FrozenLake-v0')
Q = np.zeros([env.observation_space.n, env.action_space.n])
learning_rate = .85
dis = .99
num_episodes = 2000
rList = []
for i in range(num_episodes):
state = env.reset()
rAll = 0
done = False
while not done:
action = np.argmax(Q[state, :] + np.random.randn(1, env.action_space.n) / (i + 1))
new_state, reward, done,_ = env.step(action)
Q[state,action] = (1-learning_rate) * Q[state,action] \
+ learning_rate*(reward + dis * np.max(Q[new_state, :]))
rAll += reward
state = new_state
rList.append(rAll)
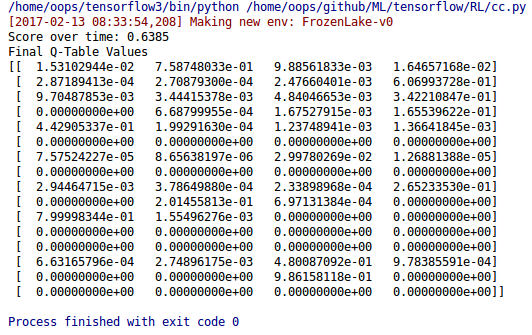
print("Score over time: " + str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print(Q)
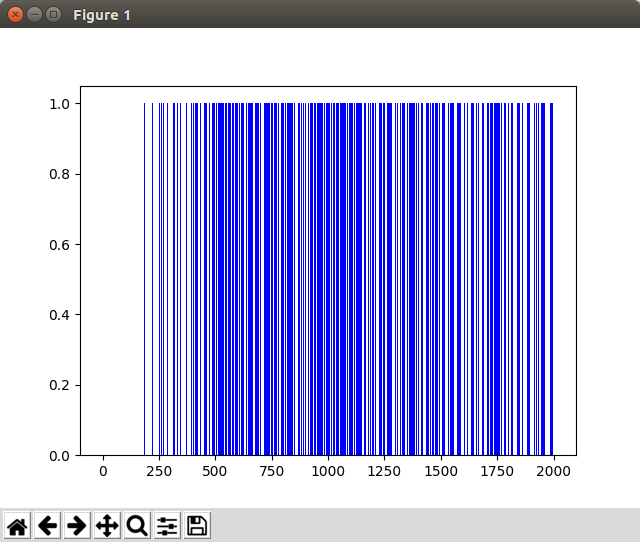
plt.bar(range(len(rList)), rList, color="blue")
plt.show()
Code: Q learning
���� ����
����